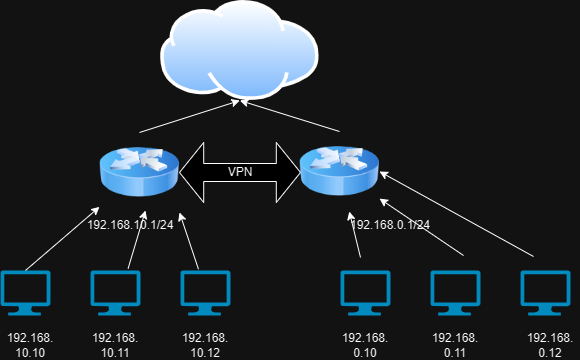
English follows Korean.
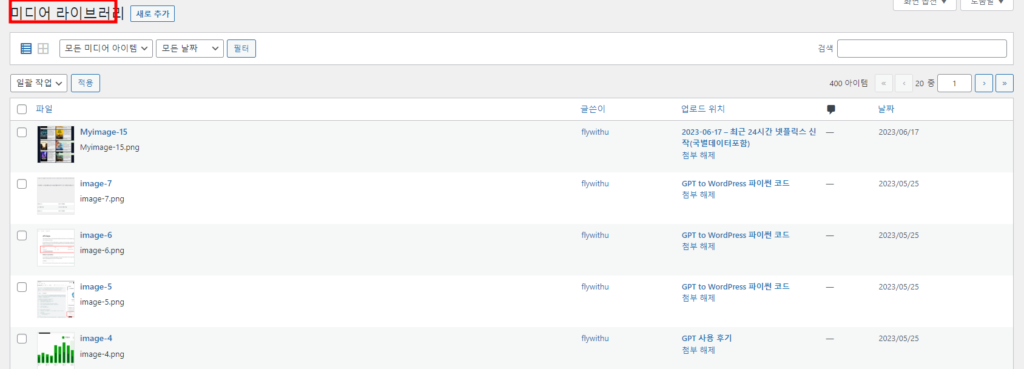
이번 포스트는 MNIST 데이터셋입니다. MNIST는 머신러닝과 컴퓨터 비전 분야에서 ‘Hello world’와 같은 존재 입니다. 이처럼 광범위하게 사용되는 만큼, 다양한 예제와 구현 방법이 널리 알려져 있습니다. 최근에 CPP로 된 MNIST를 돌려 보다가, 기존 python 보다 훨씬 빠른거 같은 느낌이 들어서 실제적인 시간을 측정해 보았습니다.
사실 python 은 GIL, 싱글쓰레드, 인터프리터, 동적 타이핑등의 이유로 CPP보다 느릴수 밖에 없습니다. 그러나 PyTorch는 많은 부분이 저수준 언어를 랩핑하는 것으로 알고 있었기에 예상보다 큰 성능차이를 보이는 결과에 대해서 상당한 의구심이 있습니다. 테스트가 잘못 되었을수도 있기 때문에, 잘못된 점을 알려 주시면 다시 확인 해보겠습니다.
테스트 결과를 보면 DataLoader와 Log Print 에서 수치적으로 큰 차이가 납니다. Python 이 Non-Blocking 으로 I/O처리는 하지만 아무래도 성능 저하가 있는것 같습니다. Log Print 의 경우는 화면에 비출력 해서, DataLoader는 속도를 최적화한 다른 API로 변경이 가능할것으로 보입니다. GPU로 복사하는 시간은 거의 동일한 것으로 봐서는, Python의 관여가 적으면 성능은 유사한것 같습니다.
가장 중요한 학습 부분에서, 초기화 – 학습 의 과정에서 아래 예시에서는 절대적 시간 차이는 적지만, %로 보면은 큰 차이를 보입니다. 이 수치와 학습 모델의 크기도 나중에 비교할 필요가 있습니다. 만약 학습 모델의 크기가 클수록 이 차이가 커진다면, PoC후 튜닝 및 상용화는 언어를 변경하는 것도 고려가 필요해 보입니다.
테스트 수행했던 코드는 colab 에 올렸습니다. 성능차이가 심한것이 아무래도 이상한데 잘못된 점이 있으면 알려 주길 부탁 드립니다. 동일한(유사한)결과를 위해 Colab 결과만 올립니다.
GPU 사용량을 추적할수 있었던 로컬 테스트 결과를 첨언하자면 GPU 사용률에서는 CPP가 월등히 높았습니다. 그러나 CPU만을 이용한 학습의 경우, CPU는 100%에 가까운 사용률을 보이나, GPU를 이용한 학습의 경우는 Cpp의 경우 50%, Python의 경우 DataLoader를 멀티로 돌릴때 30% 사용률을 보였습니다. 그래서 동시에 여러 잡을 돌려서 GPU를 100%까지 사용할수 있다면, 단위시간당 처리량은 cpp와 python이 같을수 있습니다. 이 부분은 더 실험이 필요해 보입니다.
다만 앙상블과 같은 모델을 돌려서 한개의 결과를 뽑는다고 보았을때는, CPP를 이용하는 것이 학습과 결과에 유리 해 보입니다.
각 단계별 설명은 다음과 같습니다.
Total Time: 전체 수행 시간
Summed Time: 각 스텝별 수행시간의 합. (vs. Total : Main 프로그램이 도는데 걸리는 시간 제외)
Step Count: 학습한 데이터 갯수(확인용) – 동일 수치로 두개의 모델의 일관성을 확인합니다.
Data Loading: PyTorch API를 이용한 MNIST 데이터 loading 시간 – 시간 차이가 큰 부분입니다. 언어별 효율성의 차이를 알 수 있습니다.
Copying TO GPU: 로딩한 데이터를 GPU로 복사 시간 – GPU 사용을 위한 데이터 복사 시간. 큰 차이 없음.
Optimizer Init: 초기화 – 학습 시작전 초기화 입니다. %로 보면 큰 차이를 보입니다.
Model Forward: 모델 순전파(입력 예측 생성). %로 보면 큰 차이를 보입니다. 모델의 크기에 따른 비교도 필요 합니다.
Loss Calculation: 손실계산
Backward Pass: 역전파 (가중치 조정)
Parameter Update: 가중치 업데이트
Progress Printing: Log 출력
아래의 링크로 전체 코드를 확인 할 수 있습니다.
Colab: nvcc vs. python.ipynb – Colaboratory (google.com)
| index | Func | Python(s) | CPP(s) | diff(s) | Time Difference (%) |
|---|---|---|---|---|---|
| 0 | Total Time | 145.1 | 17.9 | 127.18 | 707.80 |
| 1 | Summed Time | 142.8 | 17.6 | 125.19 | 707.51 |
| 2 | Step Count | 9380 | 9380 | ||
| 3 | Data Loading | 113.7 | 6.13 | 107.61 | 1753.01 |
| 4 | Copying To GPU | 1.32 | 1.14 | 0.18 | 16.31 |
| 5 | Optimizer Init | 2.41 | 0.10 | 2.30 | 2185.25 |
| 6 | Model Forward | 4.75 | 1.66 | 3.08 | 185.01 |
| 7 | Loss Calculation | 0.52 | 0.17 | 0.35 | 205.07 |
| 8 | Backward Pass | 13.37 | 4.71 | 8.66 | 183.96 |
| 9 | Parameter Update | 6.67 | 3.75 | 2.92 | 77.85 |
| 10 | Progress Printing | 0.062 | 0.006 | 0.05 | 846.03 |
The MNIST dataset is described as the ‘Hello World’ of Machine Learning and Computer Vision. It is widely used, with numerous examples and implementations available. Recently, I experimented with the MNIST implementation in C++, and it appeared to run faster than Python. So, I tried to check the actual time.
Python tends to be slower than C++ due to factors like the GIL, single-thread, Interpreted language, and dynamic typing. However, knowing that PyTorch wraps a lot of low-level language functionality, I expected the performance gap between C++ and Python to be minimal. But the significant differences I observed, especially in DataLoader and Log Print times, were curious. While Python used non-blocking I/O, it seems to incur some performance penalty. For log print, avoiding output to the screen and for DataLoader, using an optimized API could potentially improve performance. The time taken to copy data to the GPU was nearly identical, When Python’s involvement is minimal, the performance is similar.
In the important area of machine learning, particularly during initialization and training, the above time difference was small but proportionally significant. This indicates the need for further comparison, especially with larger size models. If bigger models make the performance gap larger, we might think about trying a different programming language before commercialization.
I’ve uploaded the test code to Colab. The significant performance difference seems unusual, so let me know of any potential mistakes. To maintain consistency, I’ve shared only the Colab results.
Additionally, I’ve observed GPU usage differences, with C++ utilizing the GPU more effectively than Python. When training solely on CPU, the usage was nearly 100%, but for C++ , the GPU usage was 50% and even lower for Python when trying with multi-threaded data loading. Perhaps maximizing GPU utilization with concurrent tasks could equalize C++ and Python’s performance. We need further investigation.
For ensemble models producing a single result, C++ seems to be more advantageous for machine learning tasks.
The table above provides a more detailed explanation of the time consumed at each step, and the full code is available at the provided URL.